面试相关
Java 基础
基本数据类型
- 整型 byte(1) short(2) int(4) long(8)
- 浮点型 float(4) double(8)
- 布尔型 boolean(2)
- 字符型 char(1)
修饰符
当前类 同包 子类 其他包 private √ X X X default √ √ X X protected √ √ √ X public √ √ √ √ 重载和重写
- 重载 :同一个类中,方法名一样,参数不同
- 重写:父子类中,子类重写父类不为private的方法
hashCode( ) 与 equals( )
- 如果两个对象相等,那么hashCode一定也相同
- 如果两个对象相等,那么equals() 为true
- 如果两个对象的hashCode()相同,它们不一定相等
java获取反射的三种方法
//方式一(通过建立对象) Student student = new Student(); Class class1 = student.getClass(); //方式二(所在通过路径-相对路径) Class class2 = Class.forName("com.xx.xx.Student"); //方式三(通过类名) Class class3 = Student.class;字符串常量池
字符串常量池位于堆内存中,用来存储字符串常量,避免开辟多个内存空间来存储相同的字符串值。在创建字符串时,jvm会首先检查字符串常量池有没有该字符串,有的话,就返回字符串常量池的字符串对象。没有的话,会在堆中建字符串,返回。
- 不变性。只读字符串,对它操作都是创建新的对象,多线程使用时,因为是不变性,所以保证了数据的一致性。
- 常量池优化。
- final。
public final class String,底层其实是char数组,private final char value[]。
集合
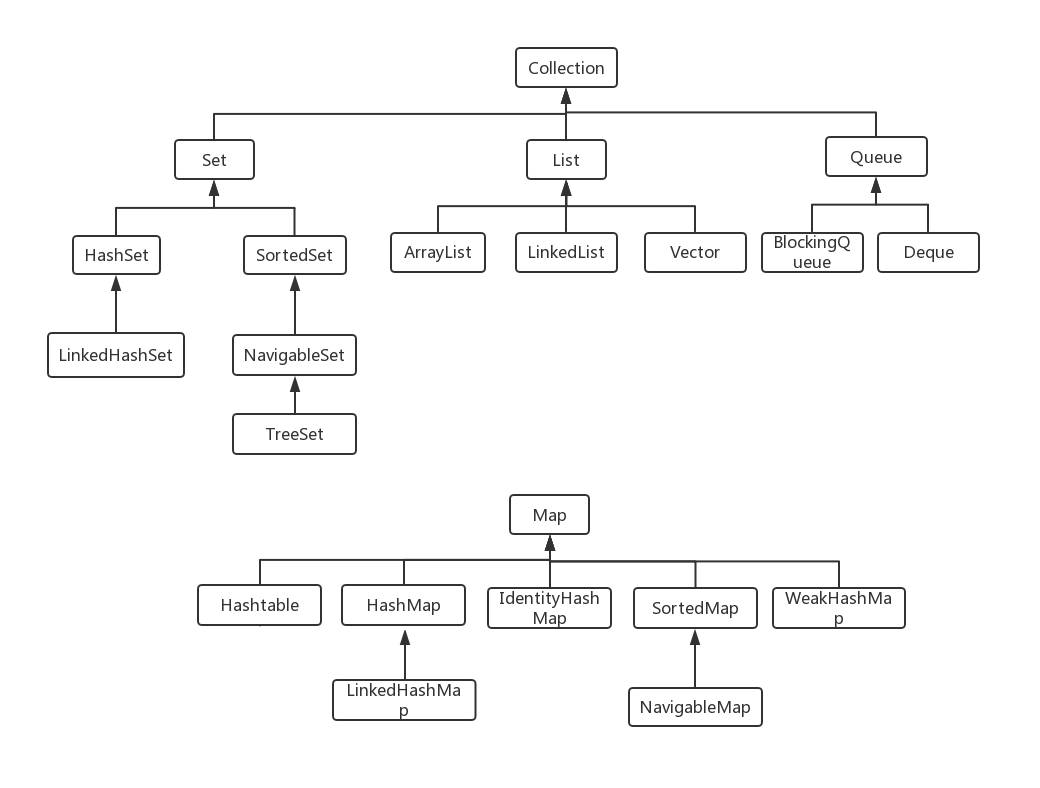
ArrayList:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable底层数组
transient Object[] elementData扩容:如果数组长度小于所需容量,那么就扩容。 如果是无参构造的空数组,最小需要容量就是默认容量10,扩容就是扩大为1.5倍的长度。
int newCapacity = oldCapacity + (oldCapacity >> 1);。扩容完复制原数组elementData = Arrays.copyOf(elementData, newCapacity);private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
HashMap
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable底层数据结构是数组+链表,jdk1.8之后,链表长度大于8时会转化成红黑树
Node<K,V>[] table, Node 实现了 Entry 接口是key-value结构
并发编程
线程创建的几种方式
- 继承Thread类
- 实现Runnable接口
线程常用的几种方法
- start() :启动线程,让线程进入就绪状态
- run():线程启动时,会调用此方法
- sleep():让线程休眠 ,进入Waiting(TIMED_WAITING)状态
- yield():让出cpu执行时间
- join():会让调用线程同步等待被调用的线程
- interrupt():打断线程。打断阻塞的线程,会报出InterruptedException异常,打断运行的线程,只会把打断标志置为true,线程仍然会正常执行。
- setDaemon() :true,设置为守护线程
线程的六种状态
- NEW:线程刚创建,还未启动时的状态
- RUNNABLE:java中将就绪和运行两种状态中统称为RUNNABLE状态
- BLOCKED:线程阻塞,等待获取锁
- WAITING:线程无限制等待
- TIMED_WAITING:线程有时限的等待
- TERMINATED:线程执行完毕,终止状态
synchronized
锁的修饰部分 锁内容 说明 例子 普通实例方法 类的实例对象 等同于this锁 synchronized void method(){ …… } 静态方法 类对象 等同于锁A.class static synchronized void method(){ …… } 代码块 任意对象锁 synchronized(任意对象) synchronized(任意对象){ …… } wait和notify
wait()是Object类的方法,作用是让当前线程进入等待状态,使用notify可以唤醒。注意:获得锁之后才能调用wait方法,否则会报错。
wait和sleep
wait 和 sleep 都是可以让线程进入休眠的状态,但是具体的又有很大的不同。
sleep wait 所属类 Thread 类中的静态方法 Object 类中的非静态方法 参数 有参 有参和无参 调用后的线程状态 TIMED_WAITING WAITING(无参时) 或 TIMED_WAITING 锁 不会释放锁 会释放锁 使用场景 任何地方都能使用 需取得锁后,才能调用 死锁
产生死锁的四个条件:
(1) 互斥:一个资源一次只能被一个资源使用
(2) 请求与保持:又叫占有并等待。进程中在等待分配其他资源时,对已经占有的资源保持不放。
(3) 不可剥夺:进程获得了资源,在未使用完之前,不得强行抢占。
(4) 循环等待:多个进程之间形成了首尾相接的循环等待关系。每个进程都占有着下一个进程所需要的资源。
ReentrantLock
ReentrantLock 和 synchronized 这两种同步方式,有相同也有不同之处,可见下表:
synchronized ReentrantLock 不需手动释放和开启锁,关键字可修饰方法,代码块 手动获取和释放锁 重量级锁 轻量级锁 可重入 可重入 不可设置超时 可设置超时 不可中断 可中断和不可中断都有 非公平锁 公平锁和非公平锁都有,默认非公平锁 单一等待队列 多个等待队列,绑定多个Condition类
Redis
五大数据类型
- String
- 字符串
- key-value 结构 ,value是单值
- Hash
- 哈希,类似HashMap
- key-value结构,value是一个key-value对象
- List
- 列表,底层实际是一个链表
- 值可重复
- Set
- 集合,无序。实际是通过HashTable实现的。
- 值不可重复
- ZSet
- 集合,有序。每个元素会关联一个double类型的分数值,分数值可以重复,值不可重复。
- 排序也是可以根据分数值来排序
- 值不可重复
- String
持久化-RDB
RDB(Redis DataBase):在指定的时间内会将内存中的数据集快照存入磁盘。会启动一个单独的线程来进行fork操作,持久化过程结束,会将这个临时文件替换调上次持久化后的文件。这样的话,主进程是不进行任何IO操作的,缺点是最后一次持久化后的数据可能丢失。
自动触发:在conf配置文件下有默认以下配置是针对RDB持久化的:
save 900 1 则表明在 900 秒内,至少有一个键发生改变,就会触发 RDB 持久化。 save 300 10 则表明在 300 秒内,至少有10个键发生改变,就会触发 RDB 持久化。 save 60 10000 则表明在 60 秒内,至少有10000个键发生改变,就会触发 RDB 持久化。
save 900 1 save 300 10 save 60 10000手动触发:使用save命令可以手动持久化,这个操作会阻塞主线程。
持久化-AOF
AOF(append only file):以独立日志的方式记录每次写命令,重启时再重新执行AOF的命令达到恢复数据的目的。
配置文件:
默认关闭,
appendonly no。要打开把no改为yes即可。持久化配置:
在配置文件中有如下配置:
always:每条 Redis 操作命令都会写入磁盘,最多丢失一条数据,但会使得Redis的性能降低,但数据几乎是全的,基本不会存在丢失数据问题。
everysec:每秒钟写入一次磁盘,最多丢失一秒的数据,对存取数据和性能折中,可以满足大部分使用场景。
no:不设置写入磁盘的规则,根据当前操作系统来决定何时写入磁盘,一般不采用这种设置。
appendfsync everysec优点:数据完整,如果配置的是每秒保存,那么丢失的也只是一秒的命令
缺点:相同数据集,AOF文件比起RDB文件要大 ;负载较高的情况,RDB性能优于AOF
缓存穿透
以用户信息为例,大量使用不存在的用户id频繁请求接口,导致查询缓存不命中,穿透DB查询依然不命中,这时就会有大量请求穿透了缓存访问DB。
解决方法:
- 对不存在的用户查询时,也要缓存中保存一个空对象进行标记,防止下次再请求同一个id。这样可能会导致缓存中出现大量的无用数据。
- 使用 BloomFilter 过滤器,BloomFilter 的特点是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存在。非常适合解决这类的问题
缓存击穿
某个热点数据失效,导致大量针对这些热点数据的请求直接查询DB。
解决方法:
- 热点数据的缓存永不过期。
- 在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
缓存雪崩
缓存挂掉,导致大量的请求访问DB。可能是某一时刻大规模的key失效,或者是redis宕机。
解决方法:
- 均匀过期:设置不同的过期时间,让缓存失效的时间尽量均匀,避免相同的过期时间导致缓存雪崩,造成大量数据库的访问。
- 分级缓存:第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
- 热点数据缓存永远不过期。
Mysql
数据库三大范式
- 第一范式。每个列不可再分。
- 第二范式。消除部分依赖。在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
- 第三范式。消除传递依赖。在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
存储引擎MyISAM与InnoDB
- MyISAM:不支持事务,表锁。非聚簇索引。
- InnoDB:支持事务,行锁,表锁都有。聚簇索引
索引
索引包含了对数据表里的引用指针,数据结构是b树或b+树。
mysql 的b树索引
b树索引是用b+树实现的。
- 所有叶子节点都包含了全部关键字的信息,及指向关键字记录的指针
CREATE INDEX index_name ON table_name (column_list);- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。
事务
事务的四大特性 ACID
原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用; 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的; 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的; 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
脏读,幻读,不可重复读
- 脏读:某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
- 不可重复读:在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读:在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
事务的隔离级别
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
mysql默认隔离级别是可重复读。
sql优化
explain sql
文档信息
- 本文作者:Aes_yt
- 本文链接:https://aesyt.github.io/2021/06/14/md1/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)